Однако существуют и другие способы закодировать информацию в нуклеотидной последовательности (и затем извлечь ее оттуда). Группа исследователей из США считает, что секвенирование (определение нуклеотидной последовательности) ДНК для расшифровки информации – это слишком дорого и слишком неудобно, так как требует специальных реактивов, оборудования, навыков. Они же предлагают использовать для декодирования частичный гидролиз ДНК, который можно легко осуществить при помощи ферментов – эндонуклеаз рестрикции. Эти ферменты вносят разрыв в двуцепочечную молекулу ДНК в определенных местах (сайтах рестрикции).
При таком способе кодирования важен размер получившихся в результате гидролиза фрагментов ДНК, а не их состав. Авторы работы говорят, что это является несомненным преимуществом: можно подбирать нуклеотидные последовательности таким образом, чтобы избежать формирования элементов вторичной структуры, или, например, подобрать желаемое GC-соотношение.
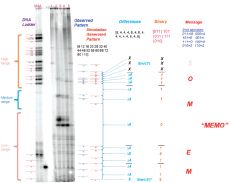
В качестве примера американские исследователи закодировали в ДНК слово «MEMOS». Расстояние между сайтами рестрикции, равное 4 нуклеотида, обозначало единицу; 8 нуклеотидов – ноль. В алфавите авторов было всего восемь букв, каждая кодировалась тремя символами. ДНК клонировали в плазмиду, амплифицировали в бактериальных клетках, выделили и подвергли расшифровке.
Авторов не смущает, что процесс «прочтения» закодированной информации включает работу с радиоактивной меткой, плотность записи составляет всего около 0,11 бит на нуклеотид, да и расшифровать они смогли лишь четыре буквы из пяти: «MEMO». Исследователи считают, что показали не просто «еще один», но более простой, дешевый, быстрый и нетребовательный способ записи двоичного кода при помощи молекулы ДНК. Вот такие молодцы.
Работа «Length-Based Encoding of Binary Data in DNA» опубликована в Langmuir.


 .
.

